Visual Deprojection Probabilistic Recovery of Collapsed Dimensions
Long-exposure photography is a kind of photography where a dynamic scene is collapsed in time to produce a motion-blurred image. In that type of photography blurriness due to motion is the main component of that photography technique. But, motion blurred and distorted dimension images get very problematic when it appears in an image and video unwantedly. To resolve this problem a team of MIT researchers has come up with an algorithm called VisualDeprojection which is elaborated in this paper. This is the first general method that handles both images and videos and projections along any dimension. The algorithm not only recovers lost details from images and videos that also creates a clear copy of the motion-blurred parts in videos and images.
<img width="360"height="220" src="https://iem-computer-vision.github.io/ICCV19-Paper-Review/images/StructureFlow_Long_exposure_photography.jpg">
Fig:3 Long-exposure photography The contributions of their paper can be summarized as follows: * They first propose a probabilistic model capturing the ambiguity of the task. It analyses the video or the image to figure out what in the video could’ve produced the blur. * They present a variational inference strategy using convolutional neural networks as functional approximators.
<img width="360"height="220" src="https://iem-computer-vision.github.io/ICCV19-Paper-Review/images/Structure_Flow_different_Projections.png.jpg">
Fig:2 Different deprojections * Sampling from the inference network at test time it yields plausible candidates from the distribution of original signals that are consistent with a given input projection. * They covered three different aspects, those are recovering images and videos from spatial projections and recovering a video from a long-exposure image obtained via temporal projection. ### 1. Model Architecture & How It Works?: The architecture of the model is based on two-parts, 1. Encoder part * Posterior Encoders * Prior Encoders 2. Deprojection Network 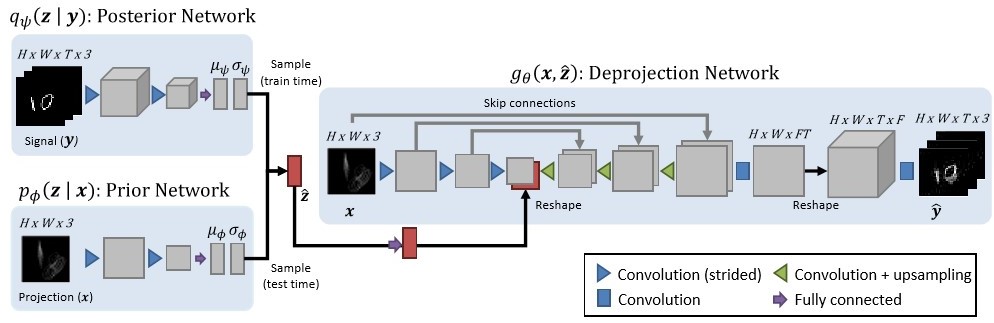
Fig:1 Model_Archetecture ### 1.1 Posterior Encoders: The encoder for the distribution parameter of the posterior is done through a series of strided 3D convolutional layers with Leaky ReLU activation on the signal(y). The whole process is continued until the volume of resolution 8x8x3 is reached. Then it is passed to a fully connected network to generate µψ and σψ, the distribution parameters, See FIg:1. ### 1.2 Prior Encoder: This is the encoder for conditional parameters Prior pφ(·|·). The main difference between Prior and Posterior encoder is that prior is implemented through a series of strided 2D convolutional layer and Posterior is implemented through a series of strided 3D convolutional layers. One z is sampled from qψ(·) during training, and from pφ(·) during the test, See FIg:1. ### 1.3 Deprojection Function: In this part, the function gθ(x, ˆz) deprojects the projection into the estimation ^y. This part of the model is basically based on UNet-style architecture which has two steps. On the first step multiclass features are extracted through a series of 2D convolutional layers and a sample of ^Z is passed through a fully-connected layer for reshaping and then concatenated with coarsest features. The second step applies a series of 2D convolutions and upsampling operations to synthesize an image of the same dimensions as x and many more data channels. Activations from the first stage are concatenated to the second stage activations with skip connections to propagate learned features. We expand the resulting image along the collapsed dimension to produce a 3D volume and then it is passed through a few 3D convs for refining and getting the ultimate result, See FIg:1. ### 2. Comparison and Evaluation Of Model: In the Spatial deprojection for Face images, they compared their model with LMMSE(linear minimum mean squared error) and DET and they found that their model outperforms LMMSE and DET in the order of producing less blurry output and their model produces a sharper image than other two at the output. Here they used FacePlace dataset. In spatial deprojection for the walking video category, they done a qualitative evaluation of their method of reconstructing human gait videos from vertical spatial projections. This scenario is of practical relevance for corner cameras. In this category, they used their own customized dataset of 35 videos of 30 subjects(more details are provided in the paper). In the temporal deprojection with moving MNIST category, excluded LMMSE in this experiment. Similar to the first experiment, this results in DET outputs having the best-expected signal (deprojection) PSNR only for k = 1. Our method clearly outperforms DET in signal PSNR for k > 1. DET performs better in projection PSNR since in this experiment an average of all plausible sequences yields a very accurate projection. * Reviewed by [Soumyadip Sarkar](https://www.linkedin.com/in/soumyadip-sarkar-173901183/)