Review of the Papper - SANet: Scene Agnostic Network for Camera Localization
This paper presents a scene agnostic neural architecture for camera localization, where model parameters and scenes are independent from each other.
The Need of SANet
SLAM, location recognition, robot navigation, augmented reality and many applications require Camera localization as a critical component. The Conventional approach is often brittle due to the long pipeline of hand-crafted components (image retrieval, feature correspondence matching, and camera pose estimation). Learning based approaches of camera localization with random forests (RFs) and convolutional neural networks often enjoy better robustness than the conventional pipeline. However, the RFs or CNNs are learned from images for a specific scene and require retraining before they can be applied to a different scene. While online adaptation is possible with RGBD query images and a RF. CNNs produce higher localization accuracy, but cannot be quickly adapted to a different scene.
For online applications such as SLAM and robotic navigation, where retraining is impossible, it is important to build a scene agnostic network for camera localization that works on unseen scenes without retraining or adaptation. By learning-based approach this paper achieves that.
This Paper have achieved state-of-the-art performance, while this method works for arbitrary scenes without retraining or adaptation.
Let’s look upon the Limitations of Related Works and how SANet comes
1)Feature Matching & Camera Fitting: The works, by the PnP algorithms focus on making the hand-crafted descriptor either more efficient, more robust, or more scalable to large outdoor scenes. However, the handcrafted feature detectors and descriptors only work with well textured images. Using VGG and etVLAD instead of hand-crafted features achieves strong performance, it is still based on the conventional pipeline of correspondence matching and camera model fitting.
2)Random Forests: These works trained a random forest to predict diverse scene coordinates to resolve scene ambiguities, to predict multi-model distributions of scene coordinates for increased pose accuracy. None of these works are scene agnostic.
As the following camera pose estimation from a scene coordinate map is a well-behaved optimization problem, recent works use CNN (Convolutional Neural Networks) to regress the scene coordinates as intermediate quantities. Their method belongs to these categories and use CNNs to predict the scene coordinate of an image. However, our network extracts hierarchical features from scenes rather than learn a set of scene-specific network parameters. In this way, their method is scene agnostic and can be applied to unknown scenes. The sequence of operation followed here is
- Constructing Pyramids
- Predicting Scene Coordinate
- Query Pose Estimation
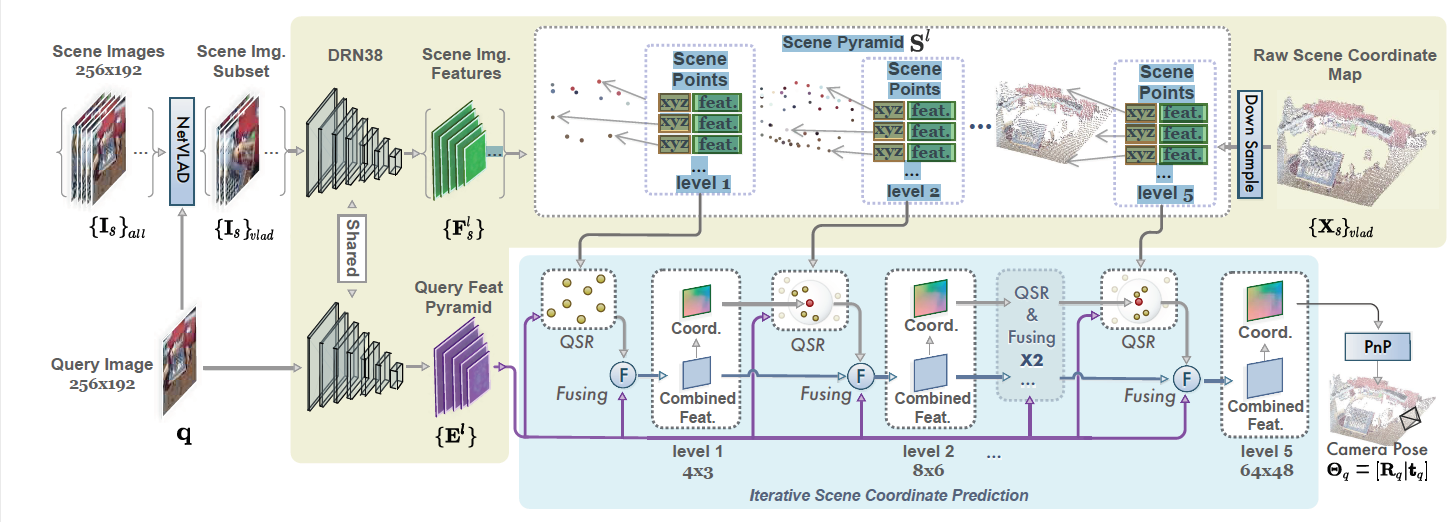
Figure 1: Pipeline of Their system. The top branch constructs the scene pyramid, while the bottom branch redict a scene. coordinate map for the query image.
How the Experiment has been done
They train and evaluate the method on both indoor and outdoor scenes and compare estimated camera poses, method efficiency, and predicted scene geometry against various scene-independent and scene-specific methods
Each training sample consists of 5 scene frames for building scene pyramid, and 1 query image. As for the Cambridge Landmarks outdoor dataset, they finetune the network using 5 out 6 scenes, and test on the remaining one. All frames in training scenes are used as query frames, and for each query they run NetVLAD to retrieval 100 closest candidate frames.
Their network is implemented with PyTorch, and trained on 1080Ti with 11G memory
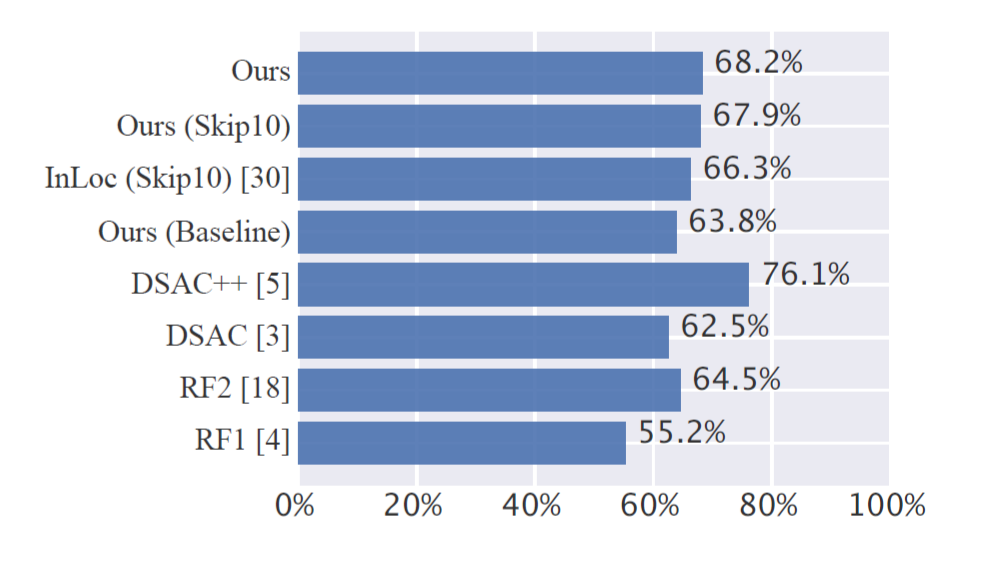
Figure 4: Percentage of predicted camera poses falling within the threshold of (5cm, 5cm) on 7Scenes indoor dataset by RF1, RF2, DSAC++, DSAC, InLoc, and their approaches.
They first measure localization accuracy in terms of percentage of predicted poses falling within the threshold of (5◦, 5cm). Figure 4 shows comparison results with other methods on 7Scenes Limited by the size of GPU memory, for each query image, they retrieve 10 nearest scene frames by NetVLAD to build the scene pyramid. The retrieval step is accelerated with knncuda library. Secondly, localization accuracy is measured in terms of median translation and rotation error.
They compare the accuracy of scene coordinate maps against InLoc and DSAC/DSAC++ on the 7Scenes dataset.
Efficiency: Their system is efficient enough for real-time scene update and query pose estimation, enabling SLAM applications
They report the accuracy of the estimated camera pose in Figure 4 and that of the scene coordinate map in Figure 6, both are denoted as Baseline. It is clear that their proposed method surpasses this baseline approach with nonnegligible margins on both evaluation metrics.
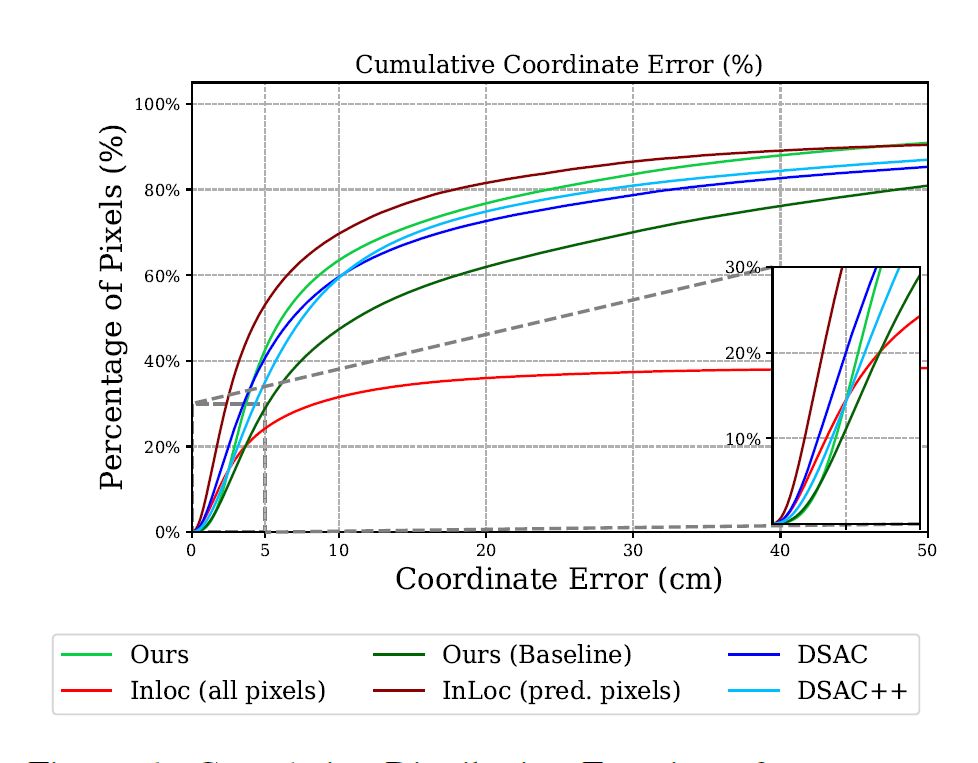
Figure 6: Cumulative Distribution Function of scene coordinate error compared with InLoc, DSAC and DSAC++ on 7Scenes.
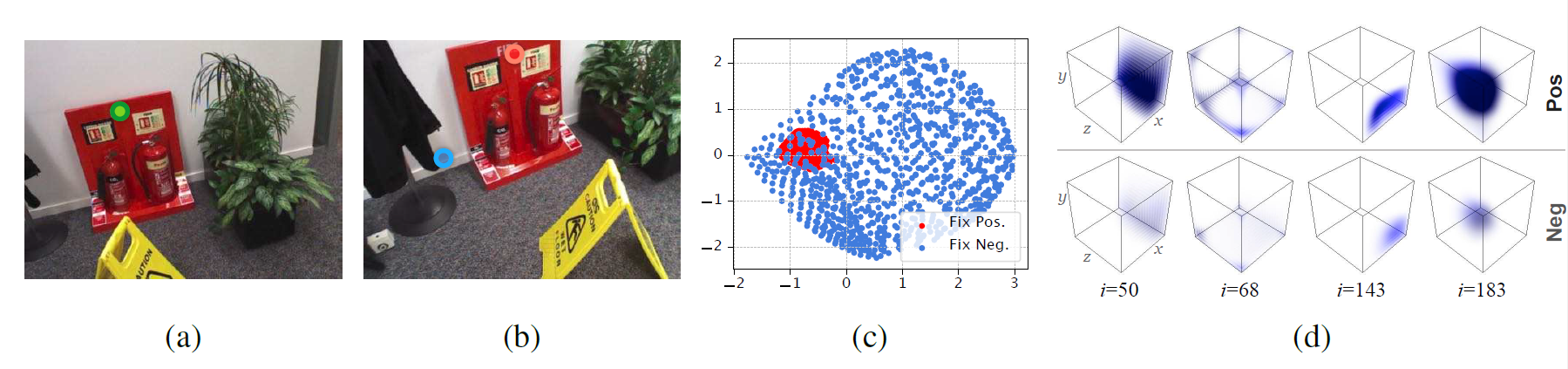
Figure 7: (a) A pixel Que in the query image is marked in Green. (b) The ground truth corresponding pixel Pos in a scene reference image is marked in Red, while a randomly selected pixel Neg is marked in Blue. (c) Two sets of scene reference features from Experiment-1 are projected in 2D space by PCA. (d) Four channels (i.e., the ith channels) of scene reference features from Experiment-2 are plotted w.r.t. a 1m × 1m × 1m cube, where dark-blue stands for high channel activation.
Therefore, the scene agnostic network architecture predicts the dense scene coordinate map of a query RGB image on-the-fly in an arbitrary environment. The coordinates prediction is used for estimating the camera pose. The network learns to encode the scene environment into a hierarchical representation and predict the scene coordinate map with query-scene registration. It iteratively registers a query image to the scene at different levels, and yields the dense coordinate map regularized by contextual image information. Their network is validated on both indoor and outdoor dataset, and achieves state-of-the-art performance. Please go to the GitHub link for code.