Shape Reconstruction using Differentiable Projections and Deep Priors
Shape reconstruction has always been an important topic of resarch in field of Computer vision. Using shape reconstruction we can determine shape profile of any object as well as coordinate of any point in the profile. It has many applications in various fields i.e Medicine, 3d- Shape recounstruction, gaming, etc. This paper gives us information about Shape recounstruction from images of an object from different projection angle by using deep prior and differentiable projection operator .
In this three differentiable projection operators are used:
- Radon Projection (TR)
- Silhouette Projection (TS)
- Depth Image Projection (TD)
Method
In this we are using following differentiable projection operators and deep shape priors for which Bayesian inference can be performed via stochastic gradient descent and their variants. In shape recounstruction we use an encoder and decoder network architecture with skip connections in which input to the network is tensor and is of same size as output. Thus, By combining the deep image or volumetric prior with differentiable projection operators, signals can be reconstructed from a few noisy projection measurements using stochastic gradient descent.
Here we are going to use this for first image recounstruction and then for 3D shape reconstruction :
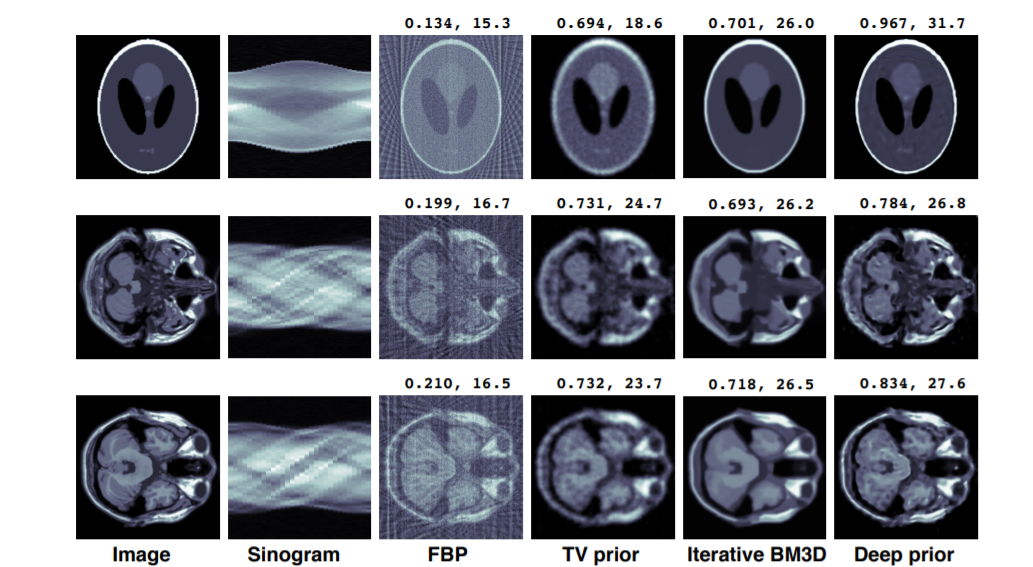
Image Reconstruction (Tomography Reconstruction):
In this several methods can be used like Filtered Back Projection (FBP), TV prior,Iterative BM3D. But the deep prior produces reconstructions with significantly better SSIM values and comparable or better PSNR values.The relatively poor performance of BM3D may be because the aliasing noise in CT reconstructions tends to be more structured and less like natural image noise when compared to the noise observed in image denoising applications.
3D Recontruction :
- Shape-from-Silhouette 3D Reconstruction : For 3D shape reconstruction from silhouette images, we employ the 3D convolutional neural network described as before to generate a voxel grid V where each voxel represents an occupancy value. The output of the network is then passed to the projection operator Silhouette Projection (TS) along with a view direction. A baseline approach for this problem is space carving, which takes the intersection of all the projected views to generate the occupancy grid. But in craving some of the objects contain artifacts like creases or even missing parts. Deep Prior reconstructs the shapes with high fidelity, preserving details and thin structures. On the other hand, space carving ends up reconstructing objects with missing parts and and rough structures

- Shape-from-Depth Images 3D Reconstruction : It is same as above but here we are using Depth Image Projection (TD) inplace of Silhouette Projection (TS). In this reconstruction ability depends on gussian noise as well as number of views avaliable.
